Linking data: what does it mean?
The basics of linked (open) data
This article is the introduction to our new ‘Linking data’ series. It defines linked data and linked open data (LOD). The rest of the series will present EU projects that use LOD. How and why do they use it? Follow the series to find out.
Data is everywhere and we are constantly producing more of it. As individuals, we create data while browsing the internet, booking a flight or shopping online. Public institutions generate data from traffic monitoring and weather tracking.
Used correctly, all of this data can bring benefits to our society as a whole and to each of us individually. It can help to create personalised medicines, fight floods and wildfires, improve public transport systems and much more. To fully live up to its potential, data needs to be accessible and available in a standardised format. This is where linked (open) data comes in.
What is linked (open) data?
There are many data sources out there and each source can have its own way of encoding and presenting information. To connect the data and create meaningful networks of information, a set of common design principles is needed.
This is exactly what linked data is: a set of design principles for publishing structured machine-readable data that allow to link it with other data. When the data is open (free to use and distribute), it is called linked open data.
Four principles of linked data
There are several features of linked data that allow it to interlink with other data. The inventor of the World Wide Web, Tim Berners-Lee, outlined four principles to define them. The four principles are the same whether the data is open or not, so in this article we use only the term ‘linked data’.
1. Use URIs as names for things
The uniform resource identifier (URI) is a sequence of characters which can give a unique name to virtually anything – digital online content, a real object or an abstract concept. The inventory number of a chair in your company’s office is its URI in that specific context. URIs allow us to distinguish things, but also to recognise things which are the same. For example, a dataset can have different names in different languages, but its URI stays the same:
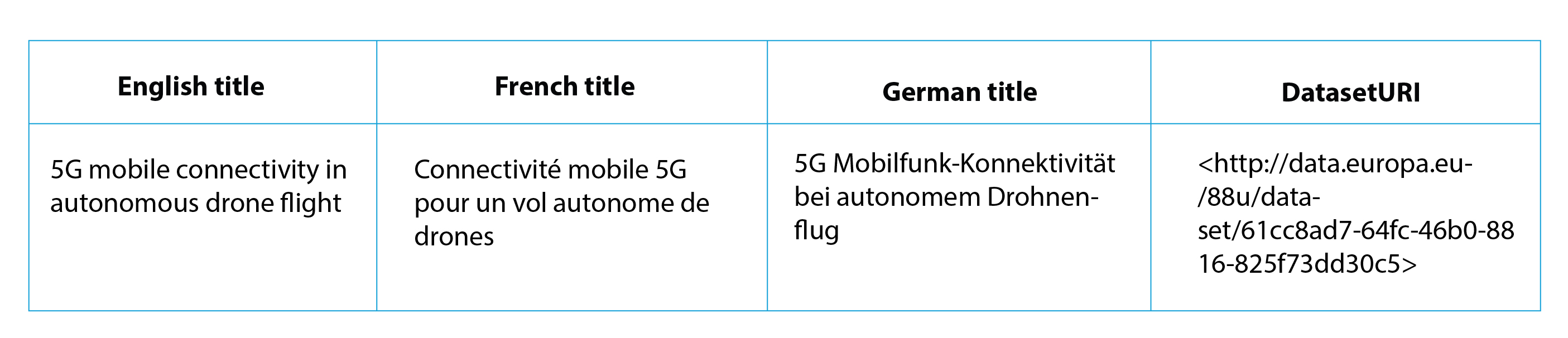
To maintain its meaning, a URI must be persistent, in other words permanently assigned to a particular resource. Imagine that your company adopts a new inventory system and that a new code is assigned to the same chair. For the chair’s URI to be persistent, the organisation will have to map the old inventory number to the new one, stating that both refer to the same chair.
2. Use HTTP URIs so that people can look up those names
Imagine that we create a dataset (in any file format) and give it a name using a URI (e.g. my-dataset). How can we allow machines and humans to easily look it up? By using hypertext transfer protocol (HTTP).
HTTP is a set of rules for transferring data (text, images, sound, video) over the internet. It is the basis of communication between web servers (where the data – our file my-dataset – is stored) and web browsers (where users can ask to access data). Whenever you type a website address into the browser and press ‘Enter’, your computer sends an HTTP request to the correct web server. Then, the web server sends you the requested HTML page – and that’s when you see the website you wanted.
The website address that you type is an HTTP URI (also called ‘URL’). The URI ‘my-dataset’ tells you ‘This is a unique resource called my-dataset.’ The HTTP URI ‘http://my-dataset’ tells you ‘This is a unique resource called my-dataset, which can be accessed via the web using the HTTP protocol.’
3. When someone looks up a URI, provide useful information using the RDF and SPARQL standards
Linked data is supposed to be machine-readable and easy to interlink with any other data. To achieve this, it is crucial to use a standard format to represent the data and to use standard query (search) language to find its metadata (information about the data).
- RDF: a standard way to describe data
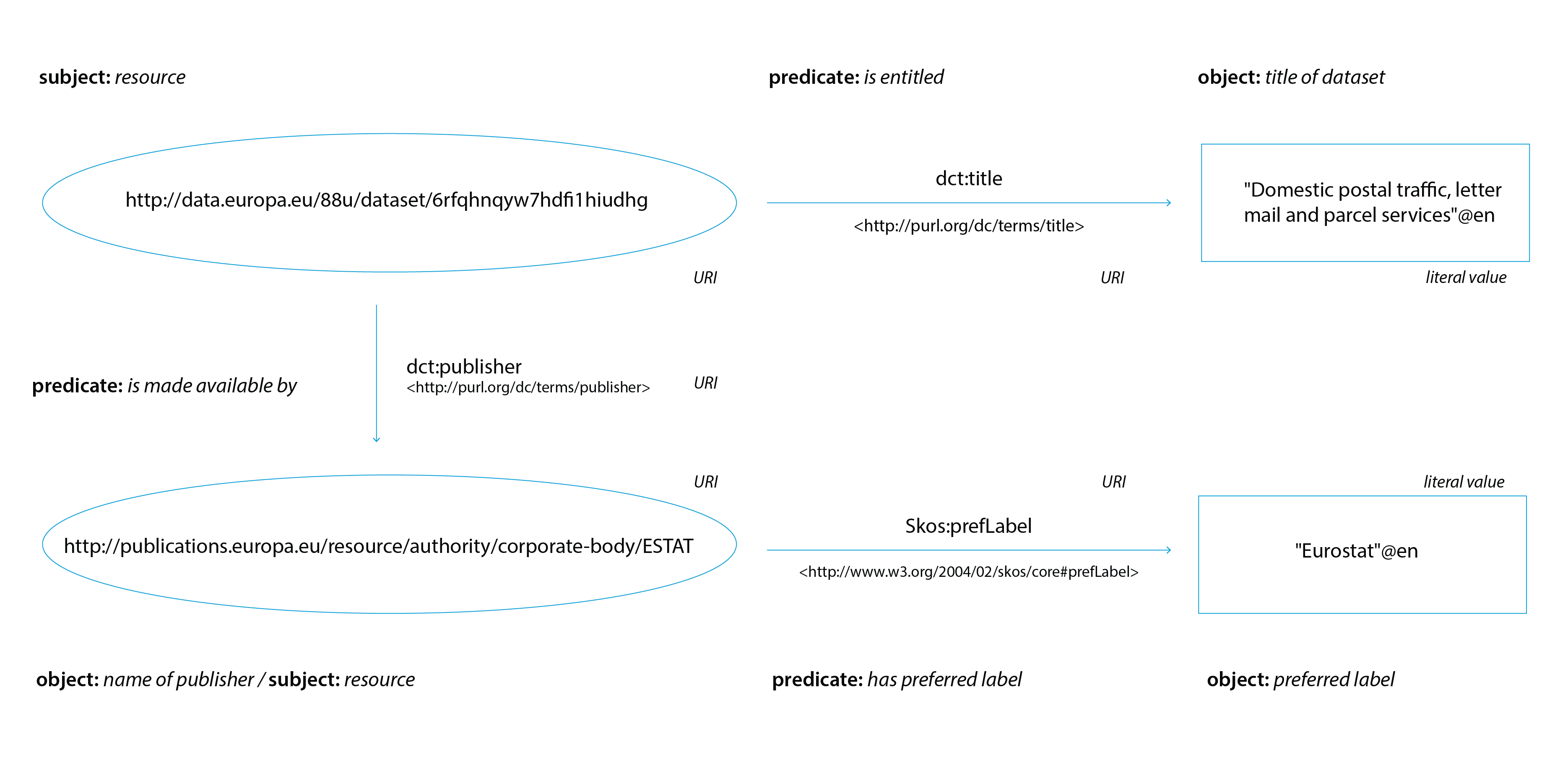
Resource description framework (RDF) is a data model currently considered as a standard way to describe data. It defines relationships between data objects using ‘triples’, based on the subject–predicate–object structure which we know from our human language.
Let’s consider the sentence ‘A dataset (subject) was published by (predicate) Eurostat (object).’ In RDF, all three parts of the sentence can be expressed as a URI. It looks like this:
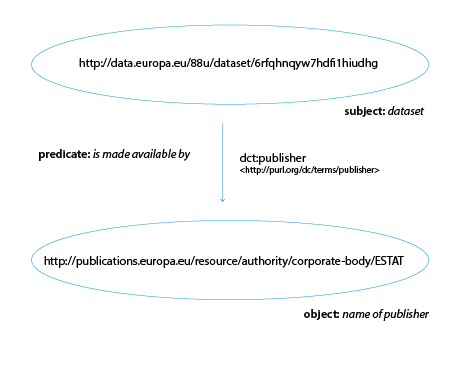
In RDF, both the subject and the predicate have to be expressed as a URI, while the object can be either a URI or a literal value (e.g. a set of numbers or letters). If the object is expressed as a URI, then it too can become the subject of a new triple, creating a bigger set of interconnected information.
- SPARQL: a standard way to search for and find data
In order to use data, people must first be able to find it. For this, SPARQL Protocol and RDF Query Language (SPARQL) can be used. It is a standardised query language to retrieve and manipulate data stored in RDF format. With SPARQL, you can search in multiple data sources in one go using ‘SPARQL endpoints’. The results of SPARQL queries can be returned in multiple formats, including RDF.
4. Include links to other URIs to discover more things
As you can see in the example above, the number of links which can be made between pieces of data using RDF triples is infinite. Why is it worth adding more and more links between pieces of data? It allows us to discover relationships between different pieces of data, gives data more context and meaning and ultimately allows us to find more information.
Enabling the ‘Web of Data’
To sum up, linked data allows to break down information silos and makes it easier to browse through complex data. The more linked data is out there, the closer we are to creating the ‘Web of Data’ – a global network of interconnected machine-readable information, as opposed to a vast collection of unconnected datasets. To ensure that everyone can benefit from the potential of today’s large amounts of data, as much data as possible should be linked and open.
Useful links
Discover the power of linked open data – video series