High-value datasets – an overview through visualisation
Exploring the origin, features and examples of high-value datasets
Introduction to high-value datasets
In light of the growing importance of data, the European Commission has recently adopted an implementing act focused on high-value datasets on 21 December 2022. As stated by both the European Parliament and the Council of the European Union, these datasets provide important benefits for society, the environment and the economy. Additionally, as hinted by their name, they are especially valuable when it comes to creating value-added services, applications and, more generally, high-quality jobs for society and the EU.
The identification and definition of these high-value datasets lead to a significant change in the field of open data, as the chosen datasets will be made available in harmonised technical standards. This aims to increase their potential for reuse and henceforth their impact.
However, defining the specific value of datasets is not a trivial task. An impact assessment study was prepared for the Commission, detailing the list of high-value datasets that were to be made available. The starting point of the study was a map of all relevant EU legislation, presenting the datasets that were already available from all EU Member States. Interviews with stakeholders then took place to develop a preliminary wish list of datasets considered to be of the highest value from an economic and social reuse perspective.
Moreover, the Commission provided the inception impact assessment, aiming to inform citizens and relevant stakeholders about its plans and open up to feedback. The document stressed the importance of high-value datasets and the need to have harmonisation rules to improve the availability of public data and its reuse.
These characteristics help overcome a series of barriers that often restrict the free circulation of information, such as high-use fees, non-machine-readable content, restrictive licences, poor interoperability or poor accessibility due to scattered data holders.
As a result of this process, a limited and well-defined group of datasets were identified. These aim to provide maximum value to their users and will be able to be used free of any technical, legal or financial barrier.
These datasets are listed in the relevant implementing regulation and are grouped in a list of six high-value datasets thematic categories: geospatial, earth observation and environment, meteorological, statistics, companies and company ownership, and mobility.
In this context, the current EU legislation provides an important guide in the choice of datasets in all six thematic categories. The first guidelines concerning PSI in the EU were produced in 1989, and since then several policy documents, studies and further legislation have followed. More specifically, PSI was regulated by the first PSI directive in 2003, the 2007 directive on establishing an infrastructure for spatial information in the European Community (INSPIRE), the second PSI directive in 2013, the 2016 general data protection regulation and, lastly, by the latest and third PSI directive of 2019, renamed as open data directive. The PSI directives were instrumental in harmonising the PSI available to the public, increasing transparency and introducing a set of measures (such as the use of machine-readable formats or central repositories) to facilitate the discovery and reuse of information produced by the public administration. This new implementing act establishing high-value datasets will be the culmination of a process developed over several years.
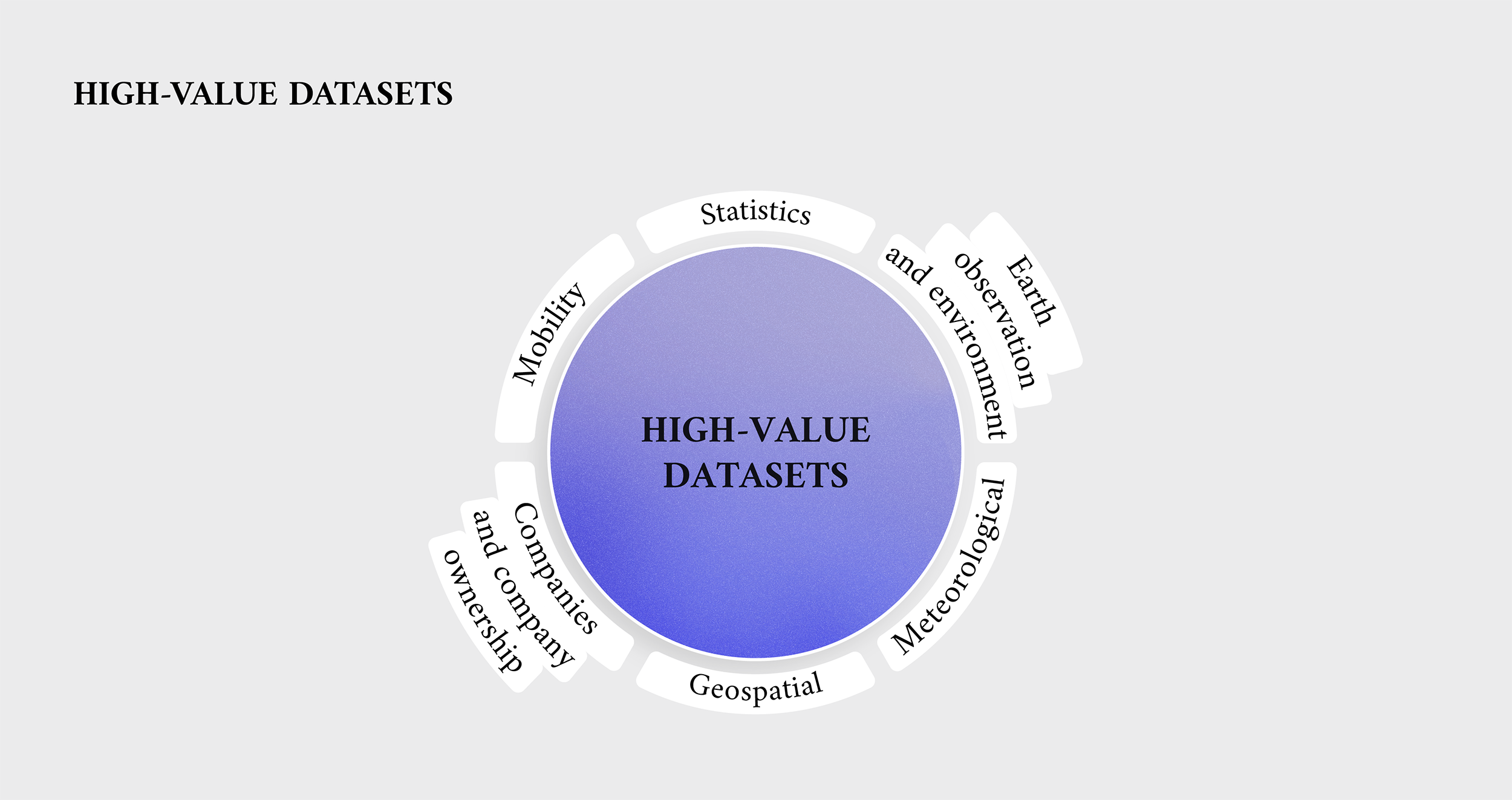
Macro characteristics of high-value datasets
The literature review conducted on those thematic categories found several macro characteristics that give them potential value. These macro characteristics include:
- economic benefits;
- environmental benefits;
- social benefits;
- generation of innovative services and innovation (innovation and artificial intelligence (AI));
- reuse; and
- the improvement, strengthening and support of public authorities in carrying out their missions (public services and public administration, social).
Each of these dimensions can help in its own way. Climate change and environment data is about exploiting information to improve environmental conditions and address climate change. High-quality, decent jobs can be created by the private sector using economic data, while innovation and AI data can help develop new applications related to algorithmic decision-making. Public service delivery can be improved using open data, with the aim of improving quality, access and efficiency. Expanding the reuse of data is of help to all stakeholders involved, as it allows them to make the most of the information already produced in the past.
These six macro characteristics are split into 32 categories of value, which were supported by a total of 126 quantitative and qualitative indicators. Through these criteria, the review assessed the value added by each of the thematic categories. More specifically, the data origin, topic covered and social impact of the data were considered, together with important technical and legal features.
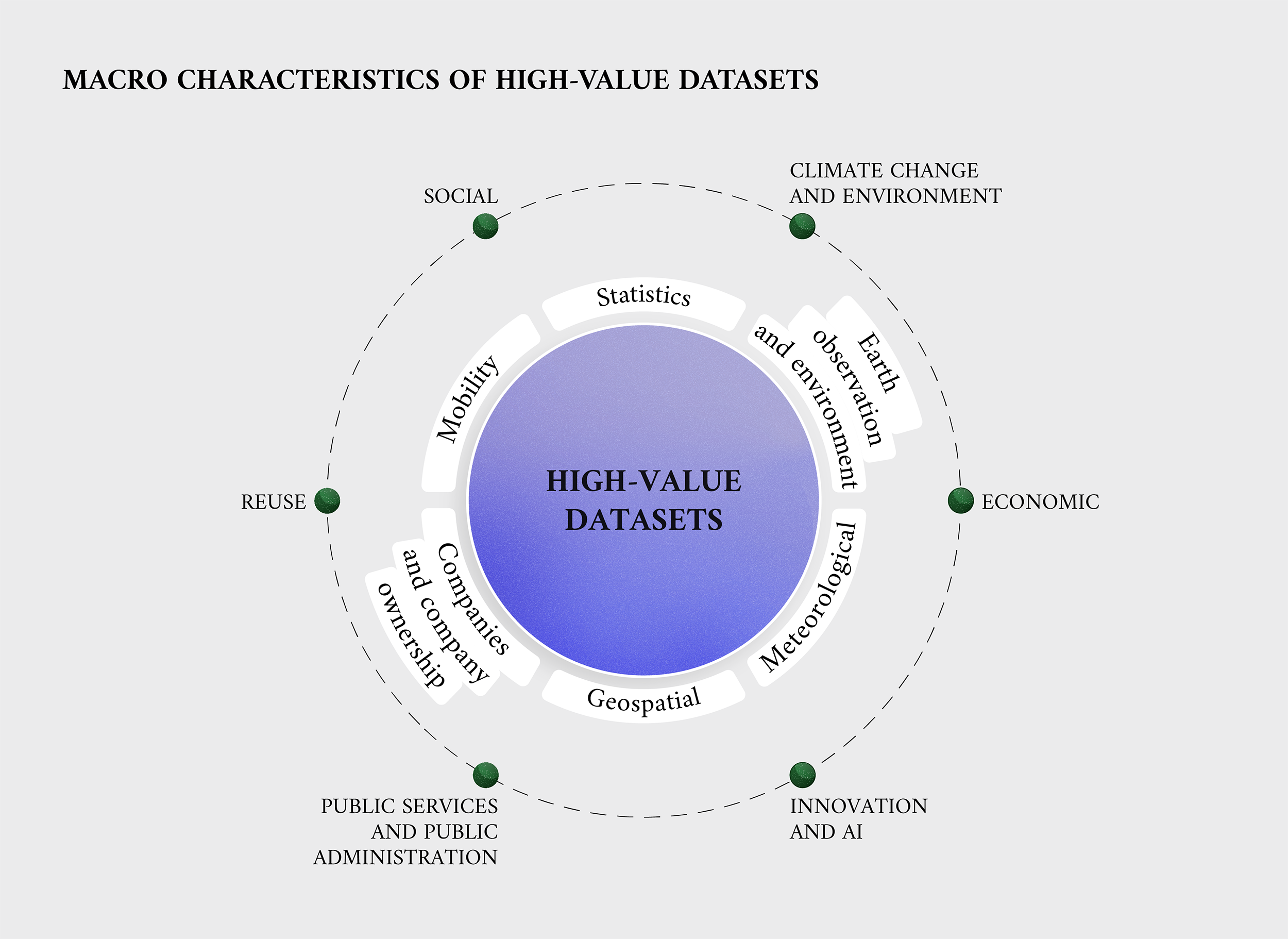
Common characteristics of high-value datasets
Withstanding some exceptions, high-value datasets are characterised by specific technical and legal requirements. The open data licence, the availability of public documentation and ensuring machine readability are all requirements applicable to these datasets. Moreover, high-value datasets are required to be downloadable in bulk (where relevant) and through application programming interfaces (APIs), free of charge, while also providing extensive documentation for their metadata.
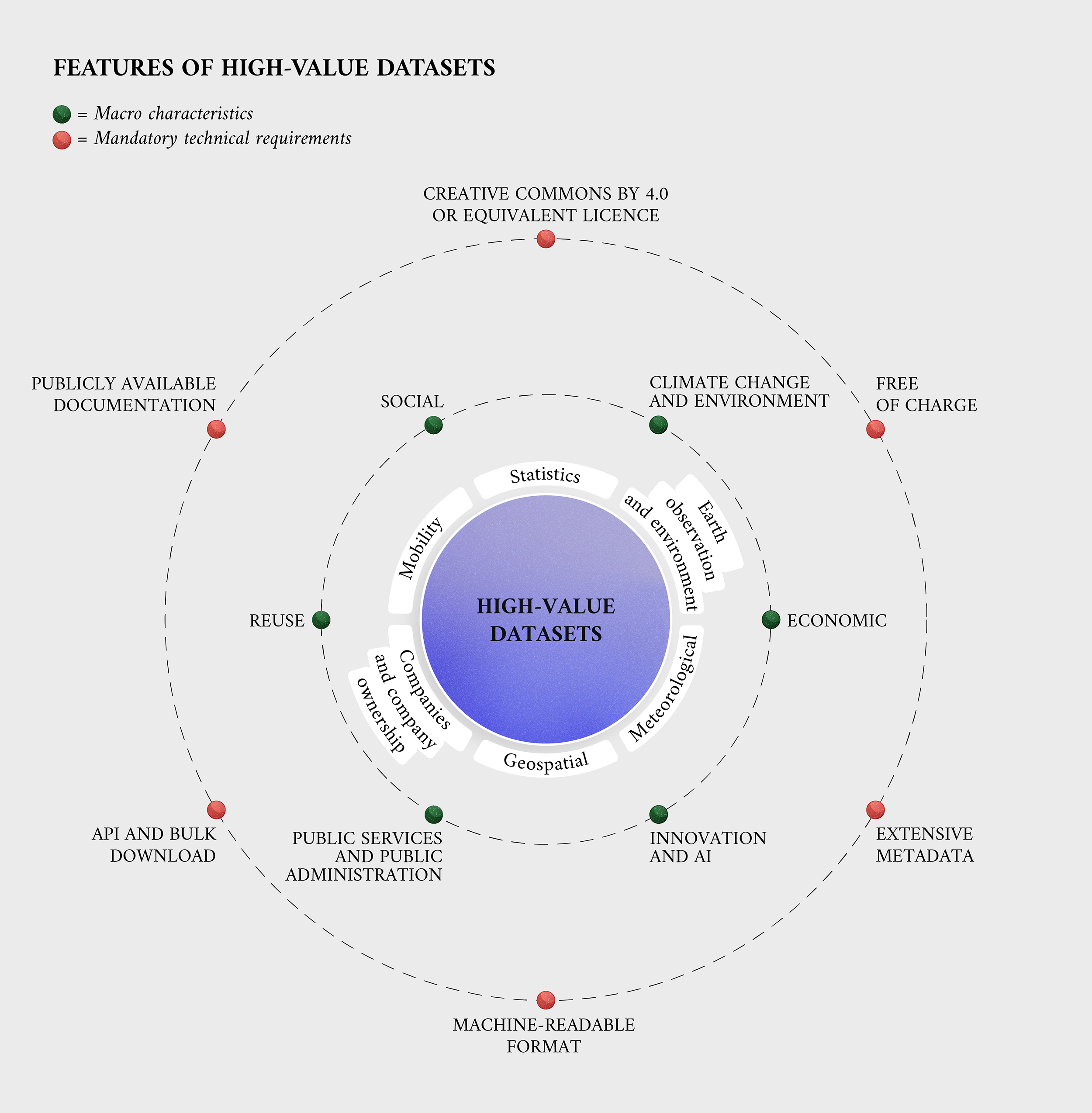
High-value datasets in practice
To better understand high-value datasets at a practical level, the annex to the Commission implementing regulation provides several examples. Geospatial datasets include postcodes, national and local maps. Energy resources and land cover are a part of Earth-observation and environment high-value datasets. Meteorological data has on-site data from instruments and weather forecasts, while demographic and economic indicators are part of high-value statistics datasets. Furthermore, business registers and registration identifier information are part of companies and company ownership data, and mobility statistics include information related to transport networks and inland waterways.
These sample datasets are part of several high-value datasets specifically defined by different legal acts, such as directives and regulations. Earth-observation and environment datasets, for example, include data about air that falls under Articles 6 to 14 of Directive 2008/50/EC and Articles 7 of Directive 2004/107/EC. This legislation regulates energy, climate and air quality. Other examples of regulations that address these categories are on nature preservation and biodiversity (Directive 2009/147/EC, Council Directive 92/43/EEC and Regulation (EU) 1143/2014), environmental noise (Directive 2002/49/EC) and the management of waste (Council Directive 1999/31/EC, Directive 2006/21/EC, Council Directive 86/278/EEC and Council Directive 91/271/EEC).
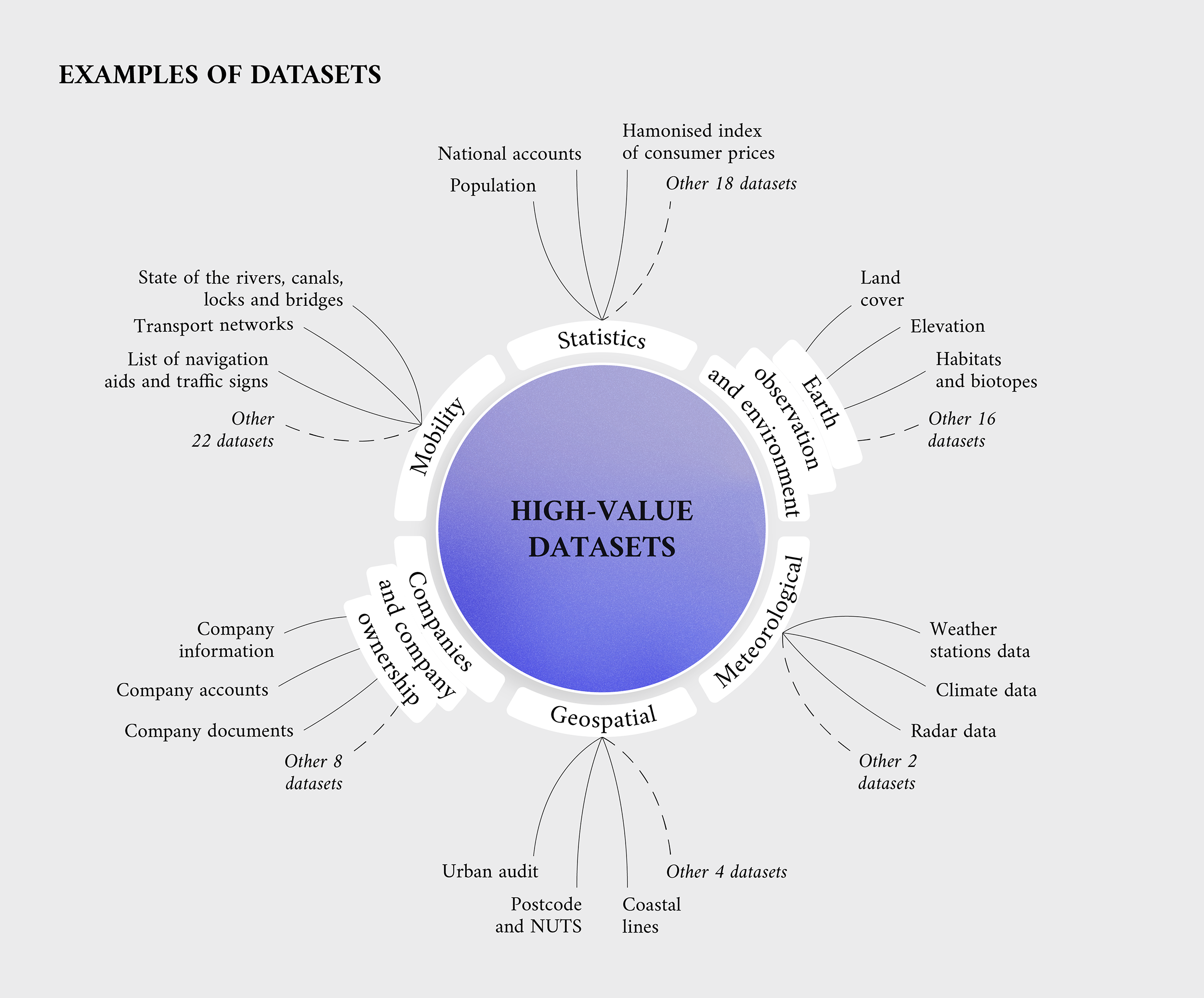
High-value datasets in detail: geospatial datasets
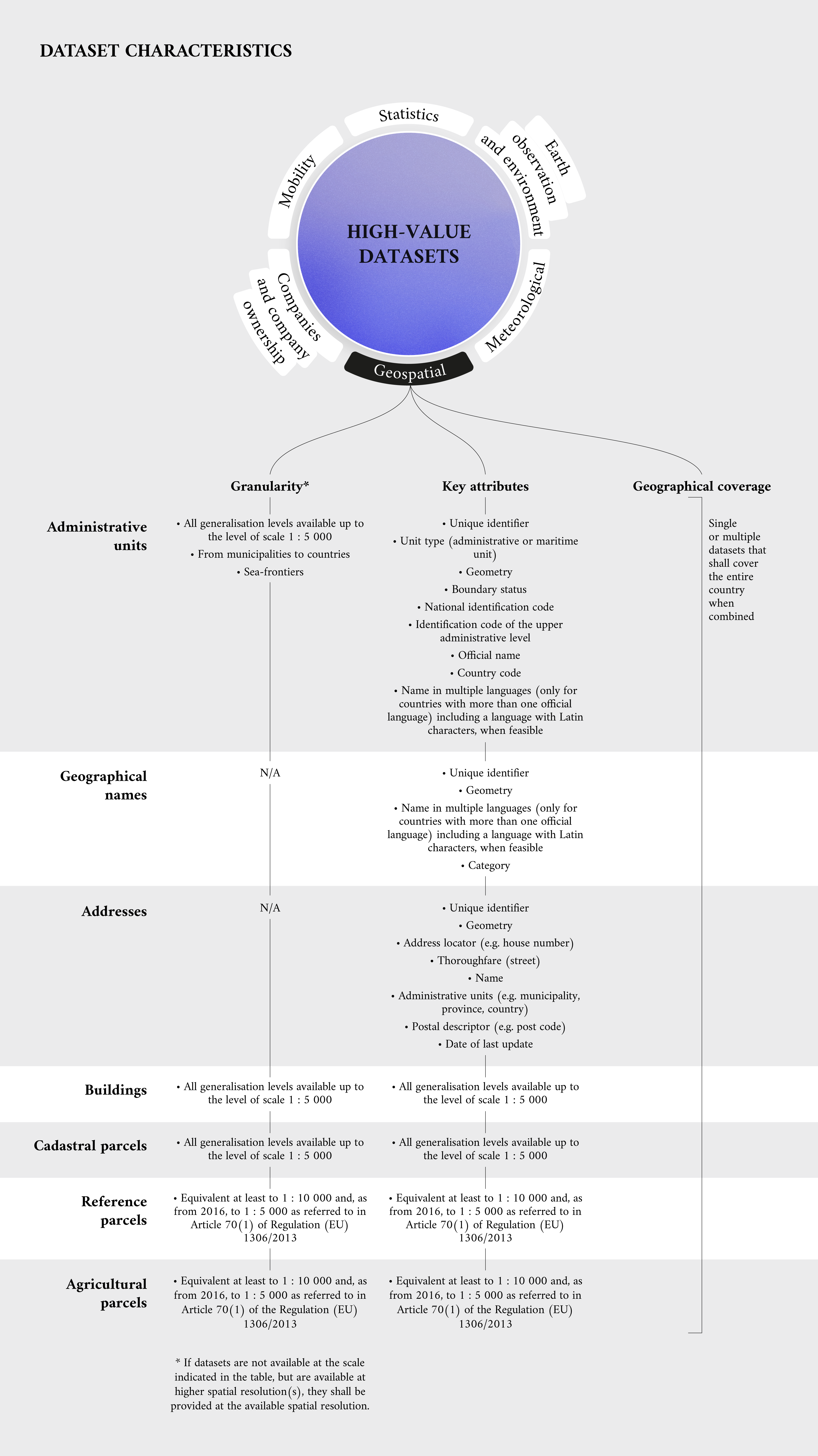
Geospatial data provides an interesting preview of what high-value datasets would encompass. As shown in the annex to the Commission implementing regulation, the geospatial thematic category includes datasets within the scope of the INSPIRE data themes. The INSPIRE directive established an infrastructure for spatial information and the European Community, identifying administrative units, geographical names, addresses, buildings, cadastral parcels, reference parcels and agricultural parcels.
The granularity of those datasets has a high variability. For administrative units, all generalisation levels are available up to the level of scale 1 : 5 000. For context, this entails data from municipalities up to entire countries. A similar scale applies to buildings and cadastral parcels, while reference and agricultural parcels may use slightly diverse levels. Therefore, the geographical coverage will allow an entire country to be covered using single or multiple datasets combined.
The information included in those datasets, belonging to a specific field, will need a unique attribute that will allow it to be identified. For example, administrative units could have an identification or country code, while buildings might use a specific geometry acting as a footprint of the building.
As mentioned, high-value datasets are defined by law, and geospatial data is no exception. For example, the INSPIRE data themes are defined in Annex I to Directive 2007/2/EC, together with reference parcels and agricultural parcels, as defined in Regulation (EU) No 1306/2013 and in Regulation (EU) No 1307/2013 and the related delegated and implementing acts setting out their granularity and geographical coverage and listing some or all of the key attributes.
Conclusion and future developments
The new implementing act on high-value datasets is an important step in improving the dissemination and reuse of information produced by public administrations in the EU. Both public and private enterprises could benefit from having access to well-documented, free-to-use statistics about the most important topics that will define the public conversation in the coming years.
As several studies have shown, previous legislation has had a large, positive economic impact. The new implementing act will free other significant datasets, further extending the scope of what people can do with information and keeping publicly produced data in line with rapid technological changes.
High-value datasets and its six thematic categories will be the focus for a series of data stories supported by data visualisation that will be published on data.europa.eu.
To download the visualisations, click on the following: HVD overview, HVD macro characteristics, HVD features, HVD examples, HVD characteristics.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Article by Davide Mancino
Data visualisations by Federica Fragapane