Linking data: data.europa.eu
How linked open data standards help to connect public sector data in Europe
In our ‘Linking data’ series, we present EU projects that use linked open data (LOD). You may be wondering, what data is linked in their projects? Why did they decide to use LOD? What benefits does it bring? Follow the series to find out.
In this episode, we will take a closer look at data.europa.eu, the official portal for European data.
Central point of access to public sector data in Europe
In the EU, the public sector is one of the most data-intensive sectors. Public sector bodies produce, collect and pay for vast amounts of data, known as public sector information or government data. If those government data can be freely accessed and reused, we call them open data.
Reuse of public sector information can generate important value for the economy and society. A prerequisite to make such reuse possible is that it is easy to find and access the data. Therefore, the EU institutions, together with national open data portals, set up and manage data.europa.eu, the official portal for European open data.
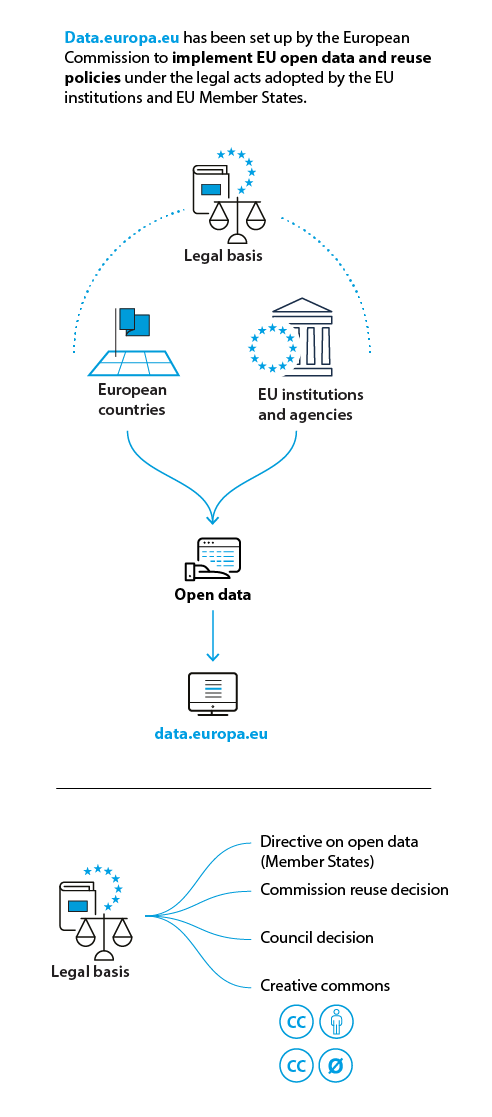
Data.europa.eu is a platform that provides a central point of access to data made available by the public sector in Europe.
By providing metadata about and linking to data sources, the portal currently gives access to open data resources from 36 European countries, EU institutions and agencies, and international organisations. It allows everyone to easily search, explore, link, download and reuse the open public sector data for commercial or non-commercial purposes.
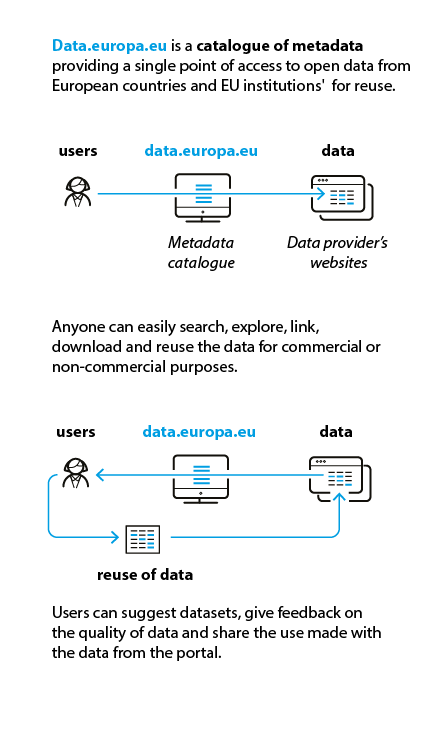
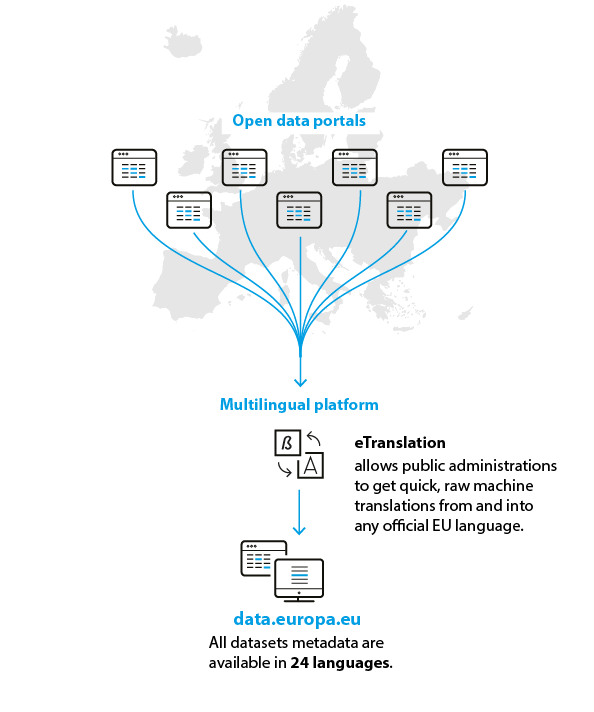
Metadata of datasets on data.europa.eu is encoded as Resource Description Framework (RDF) triples, using a common application profile of the Data Catalogue Vocabulary (DCAT) web ontology (DCAT-AP). Triples are a subject–property–object declaration where the subject is the item being described, property or attribute is what is being described and object is the statement being made. For example, a dataset title is always encoded as the same type of property, whether it comes from a local geo-data catalogue or Eurostat. Furthermore, titles are made available in all 24 official EU languages by machine translation, all using the same property.
DCAT-AP uses specific controlled vocabularies, many of which are maintained by EU reference data. Our previous data story on EU vocabularies shows how reference data promotes LOD. Using controlled vocabularies ensures that datasets are described in a harmonised way, which, in turn, helps to explore the datasets and find new connections between them.
For example, data.europa.eu offers the possibility to browse all the datasets by topic, according to 13 thematic categories. This is implemented using a multilingual controlled vocabulary with 13 terms (one per thematic category), which allows datasets from different catalogues and in different languages to be automatically linked, based on the selected thematic category.
How does it work? The term for each category is in fact a unique resource identifier (URI) taken from the EU vocabulary data theme. For example, the ‘Health’ category refers to the following URI: https://publications.europa.eu/resource/authority/data-theme/HEAL, whether the thematic category label of the dataset’s metadata says ‘Health’, ‘Υγεία’, ‘Gesundheit’ or ‘Egészségügy’.
The same is true for terms describing the language of a dataset, the country where its publisher resides, the file format, etc.
Imagine wanting to find a large set of textual data, in two given languages, to train an artificial intelligence application to create automatic translations. The DGT translation memory dataset is one such example. Having terms for file types and languages indicated as URIs means that this search can be executed automatically (e.g. using SPARQL queries).
In fact, another principle of LOD is that all (meta)data should be searchable via SPARQL. Data.europa.eu allows all RDF data to be searched via the SPARQL endpoint. SPARQL queries can also be submitted via the user interface based on Yasgui (a query editor), making it easier for humans to manually query the data. These pages also include references to the standards used and sample queries.
Finally, thanks to DCAT, datasets on the portal can be intentionally and directly linked to each other. For example, the data provider can indicate in the dataset’s metadata that dataset X is a version of dataset Y.
Future enhancements of the portal will be able to use artificial intelligence to detect such relationships and declare them in a standardised way.
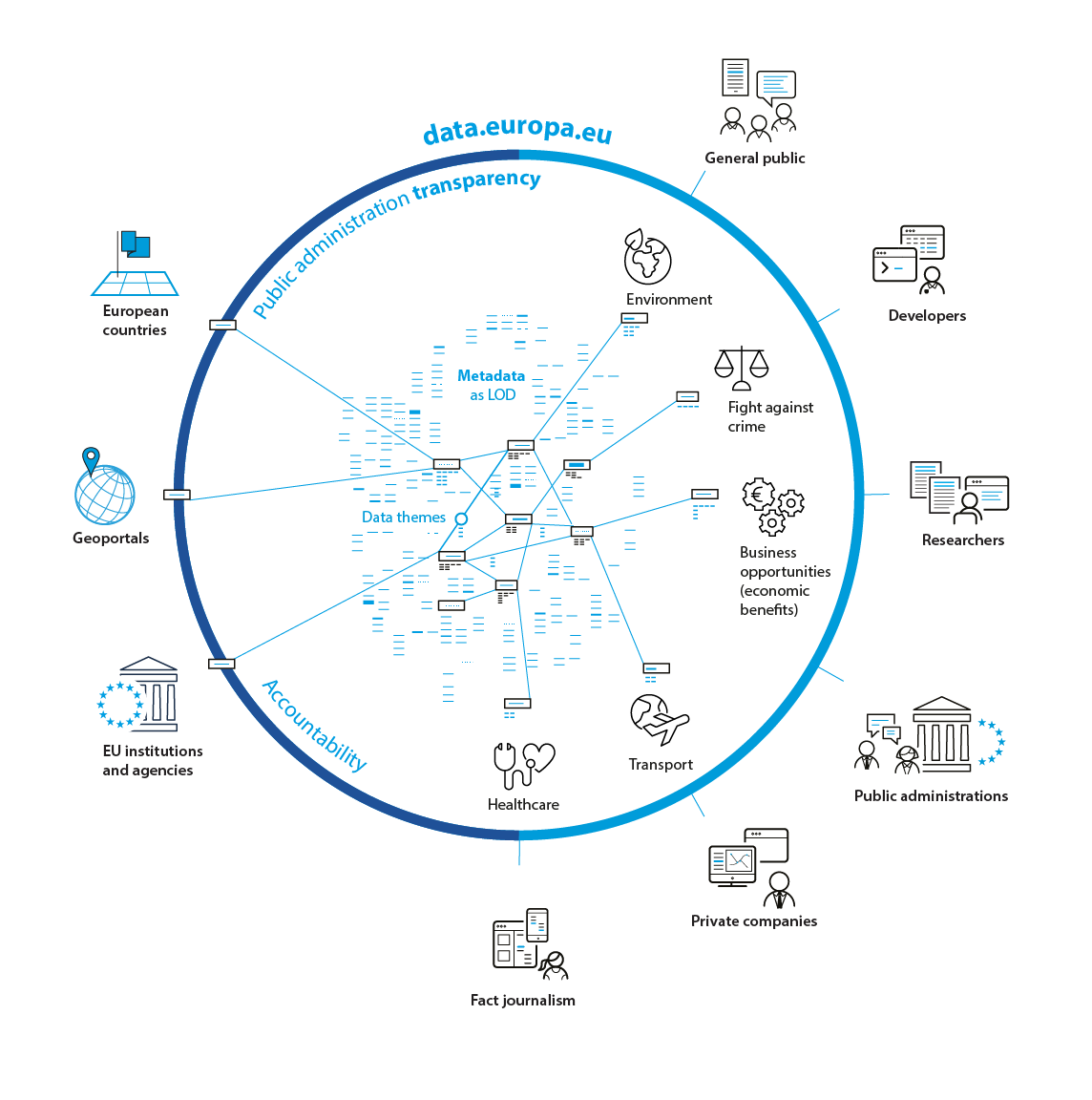
The benefits of the LOD approach
The most obvious benefit of the LOD approach is that data can ‘talk to each other’ and that humans and machines can understand them in a correct way. LOD also enables machine-to-machine access. It is particularly important as it allows devices to exchange information and perform actions without human assistance.
All this, in turn, allows everyone to reuse the vast amounts of available data more easily to build apps, data visualisations or combine data from different publishers and sources and create new datasets for specific needs.
The more data-driven solutions and resources are out there, the easier it is to communicate complex information, make informed decisions and solve problems effectively.
Useful links
Data.europa.eu SPARQL endpoint: query editor, machine access
Data.europa.eu application programming interface
Linked data solutions: pilot catalogue on EU knowledge graph
Graphics used in this article (available for reuse under CC-BY-4.0)